
The Question Your Portfolio Review Never Truly Answers
The efficient frontier tells you which bets clear the hurdle. It never tells you whether the survivors can be staffed by the same scarce people in the same quarter.

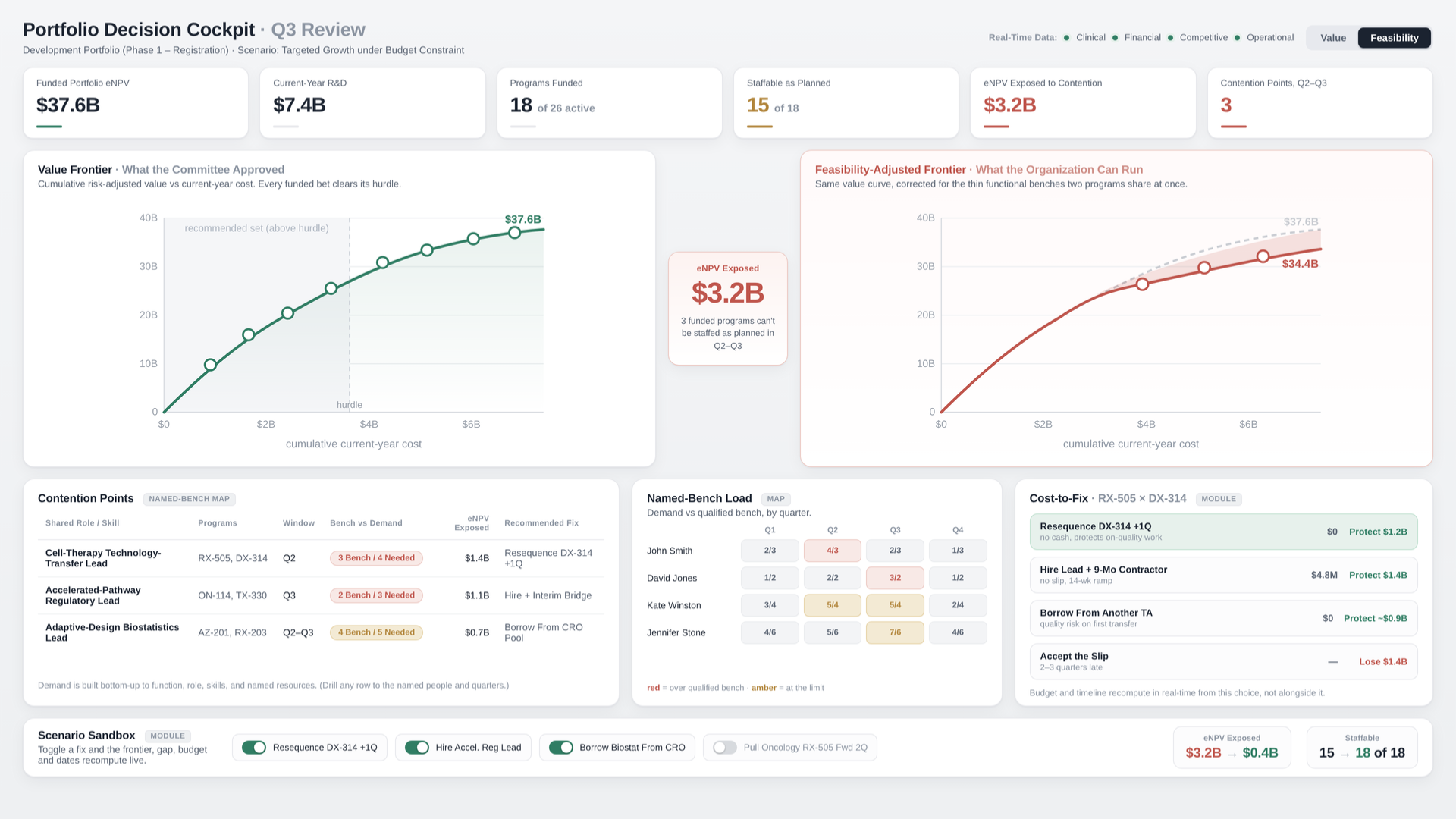
You can rank every bet, value every asset, and stress-test every scenario, and still walk out of a portfolio review without knowing the one thing that decides whether any of it happens: can the revised book of work actually be executed?
Picture a portfolio committee that has done everything right. The job today is to reprioritize, trim an existing pipeline that no longer fits the budget, and resequence what survives (an exercise currently running in nearly every R&D organization). Every asset carries a risk-adjusted value. The efficient frontier is on the screen, a clean curve with the recommended portfolio sitting right where return stops rising fast enough to justify the spend. Fund these four. Pause that one. Pull the lead oncology program forward two quarters to beat a competitor to readout. The analytics are current, the logic is sound, and by every number on the screen, the recommendation is correct. Everyone signs.
Six months later, two of the funded programs are behind, and not for any reason that appears in the model. The science is fine. The strategy was right. Both programs reached process development in the same quarter, and both needed someone who had actually run tech transfer for this class of molecule, the kind of work where doing it once badly costs you a year. The company had perhaps three such people. Two were already committed elsewhere. The model had carried process development as a number, so many FTEs in the second quarter, a pool. It had never carried the fact that the pool was three people deep and two programs wanted all of them at once. The portfolio was optimal. It just could not be staffed.
This is the question every portfolio review asks and almost none truly answer. Not "which bets are worth making," which we have gotten good at. The prior question, the one that decides whether the answer to the first one means anything: can we execute the book of work we just approved?
We Debate the Bets, Not the Bench
Pick up any serious treatment of pharma portfolio decisions and you will find the same preoccupations, all of them legitimate. The biases that distort the choice: a 2023 review of pharmaceutical portfolio management put confirmation bias, champion bias, and misaligned incentives at the top of the list of forces that bend decisions away from evidence. The governance that ought to discipline them: who sits on the committee, who owns the decision right, how the stage gates are run. And the hardest one of all, the courage to kill, the program everyone knows should die but nobody will be the one to end.
These are real problems, and I have written about the last one before. They share a property worth noticing: every one of them is about choosing the bets. Which to make, which to stop, which to defend. The entire intellectual energy of portfolio management points at the selection.
Almost none of it points at execution. Once the portfolio is chosen, the question of whether the organization can actually deliver it, given that the programs draw on the same finite set of people, gets treated as someone else's problem, downstream, in a different system, after the decision. The selection is strategy. The execution is logistics. And logistics does not get a seat at the portfolio table.
That division is the gap this discussion is about. Not a flaw in how we choose. A silence about whether the choice can be run.
The One Input Still Estimated, Not Computed
The strange part is that the silence runs against the trend. Portfolio management has spent a decade getting less static, not more. Clinical data now flows into the portfolio view as trials enroll. Financial actuals update from the ledger. Competitive intelligence refreshes as rivals read out. The direction of travel across the industry is toward what its practitioners call an evergreen portfolio, four dimensions, clinical, financial, competitive, and operational, synthesized continuously rather than rebuilt once a year for the budget cycle.
Three of the four are now live. The fourth, operational, is broader and more uneven; parts of it, enrollment, milestones, supply, are catching up. But the corner of it that decides feasibility, the resource picture, who is actually free to do the work, when, and can do the specific work well (better than most), is the part still built from a template rather than computed from the work. That is the exception that matters, because resourcing is the input that determines whether the plan is physically possible at all.
Walk into almost any organization and look at how the resource side of the portfolio is actually built. Demand comes from an algorithmic template: a program of this type needs roughly this shape of team, derived from how programs like it have gone before. Capacity is a set of pools: so many clinical operations FTEs, so many regulatory leads, so many process-development specialists, by quarter. The numbers are maintained mostly by hand and refreshed when someone finds the time. This is the same gap between an estimate and a calculation I have described before in the context of single programs, a parametric average standing in for the actual work, except now it is doing that job for the whole portfolio at once.
A pool cannot tell you that two programs are about to reach for the same thin bench of specialized resources at the same moment. That information does not exist at the altitude of "twenty process-development FTEs in Q2." It exists one level down, where the two tech transfers are real pieces of work with specific people attached, and the model can finally see that the handful qualified to do both are the same handful, unable to be in two places at once. Keep resources as a pool and the collision stays invisible, not from carelessness but because the pool has nowhere to put it.
This is the part the word "resource" hides. No individual is irreplaceable; that is not what I'm saying. What I mean is this: for the work that actually gates a program, the bench of people who can do it well is thin, often only two or three in the entire organization, and grown over years, not hired off the market. When several programs need that bench in the same window, the schedule does not bend gracefully. One program waits, or the work goes to someone who has not done it before, and either the timeline or the quality pays for it. A pool of thirty hides a bench of three, and the bench of three is what determines whether the plan was ever real.
It's not that the tools ignore resources. Most of them have a resource module, a capacity view, a supply-and-demand chart. The truth is narrower and more uncomfortable: the resource dimension is the last one still fed top-down, periodically, at pool resolution, while every dimension around it has moved to something live and granular.
The Numbers Ride on the Weakest Input
Once you see the resource picture is the fuzzy spot, a second thing follows, and it should worry a CFO.
The budget and the timeline are not independent of the resource model. They are derived from it. A program's cost is mostly the cost of its people over the months they are on it; its schedule is mostly a statement of when those people are free. Resources are the parent variable. Budget and timeline are its children.
So when the resource layer is a top-down template, the budget and the schedule built on top of it inherit every imprecision underneath. Prioritize the oncology program, pull it forward two quarters, and the model dutifully recomputes its cost and its dates. What the model cannot recompute, because it cannot see it, is that pulling oncology forward just claimed the one regulatory lead who had run this accelerated pathway before, the same person the other submission was quietly counting on, so the second program's timeline has moved and its cost has grown, and neither change appears anywhere on the screen. The portfolio's numbers are precise. They are also wrong, and they are wrong in a particular direction: they describe a book of work lighter and faster than the one the organization actually signed up for.
A resourcing leader I spoke with described the lived version of this better than any model could. When a new study lands and someone has to find the people for it, the team moves things around, and the moves ripple into programs run by people they never spoke to, in functions they were not thinking about. "No one ever talks to each other," she said, "because those scenarios don't make it to those ears. And then all hell breaks loose." The coupling was always there. It surfaced as a crisis instead of a number because the only place it became visible was the hallway, six months too late.
I want to be precise about the size of my assertion, because it is easy to overstate and the overstatement is where credibility dies. This is not why drugs fail. Most clinical attrition still comes from biology, efficacy, safety, pharmacokinetics, the hard fact that many drugs simply do not work well enough in humans, and no operating model can rescue that. Resource coupling does not explain a single failed trial. What it explains is narrower and entirely within our control: why the portfolio you approved is not the portfolio you can run, why dates slip and costs creep in ways that trace back, every time, to a thin bench two programs were silently sharing. The science decides whether the drug works. The coupling decides whether the plan was ever real.
The Barrier Is No Longer Technology
The encouraging part is that the barrier here is no longer technology. The reason resources stayed a top-down template for so long was practical: building demand bottom-up, task by task, for every program, and keeping it current as the work changed, was weeks of manual effort that went stale the moment it was finished. So organizations did it once for the budget cycle and let it rot. That constraint is the one that has actually lifted.
Three things change the picture, and they have to happen in this order. The demand has to be derived from the bottom up, from the actual work each program entails, so it resolves to function, role, and named skill rather than a pool. The contention has to be discovered automatically, the system noticing on its own that two programs will need the same tech-transfer lead in the same quarter, rather than waiting for someone to model the dependency by hand after it has already bitten. And the budget and the timeline have to be computed from that resource truth, downstream of it, so they move when the resource reality moves instead of being asserted alongside it.
Get those three right and the portfolio review changes character. The efficient frontier is still there, still useful, but it now sits on top of a feasibility check that was never available before. The recommendation comes with the one thing the beautiful curve never carried: an answer to whether the book of work can actually be staffed, where it cannot, and what it would cost to fix, all visible before the committee commits rather than after the program stalls. The question stops being rhetorical.
None of this displaces the work of choosing well. Bias, governance, the discipline to kill, those remain the hard human core of portfolio strategy, and no system resolves them. What changes is that the choice finally gets tested against the constraint that was always going to decide its fate, instead of being handed to logistics to discover the hard way.
The Risk Lives in the Edges
The deepest habit to break is the one hiding in the language. We call it a portfolio, and the word carries an assumption: a collection of holdings, each valued on its own, summed into a total. Rank them, weight them, draw the frontier. That picture is exactly the one that hides the problem, because it treats the programs as independent, and they are not. They are joined, under the surface, by every person, every function, every facility they have in common.
A portfolio is not a ranked list of independent bets. It is a contention graph. The risk does not live in the assets. It lives in the edges between them, where two programs reach for the same thin bench in the same narrow window, and one of them has to wait. Optimize the assets and ignore the edges, and you have optimized the part of the picture that was never going to be the problem.
The Worst Time to Be Guessing
This is the season for it, and the season sits on top of a longer trend. For half a century, the number of new drugs approved per inflation-adjusted R&D dollar has roughly halved every nine years, a slide in research productivity so persistent it earned a name, Eroom's Law, Moore's Law spelled backwards. The lesson buried in it is that the gains still on the table come less from better science, which stays hard, than from better decisions and cleaner execution, the other half of the problem, and the one that is actually ours to fix.
The patent cliff is the acute version of that pressure. Depending on the estimate, more than $200 billion of branded revenue, and by some analyses over $300 billion, faces loss-of-exclusivity exposure by the end of the decade, and the industry's answer, visible in every quarterly call, is to reprioritize: trim the pipeline, concentrate the spend, revise the book of work. Every one of those revisions is a portfolio decision made at speed and under pressure, which is precisely when the unseen constraint costs the most. We are about to make more of these calls, faster, than at any point in a decade.
So before the frontier goes up on the screen again, it is worth asking the question the review is built to ask and rarely built to answer. Not just which bets are worth making, but whether the people who would have to make them real are the same people, at the same moment, on more than one bet at once. The committee should see not just the value, the cost, and the timeline, but the named contention points that make those numbers true or false. Find out who your programs share. The portfolio you can execute is the only one you actually have.
References
McKinsey & Company, "Strengthening the R&D operating model for pharmaceutical companies."
"Pharma Faces $236 Billion Patent Cliff by 2030."
Further Reading
The Kill Decision Problem: Why the Hardest Portfolio Choice Is the One Nobody Wants to Make. On choosing which bets to stop. This piece is its companion: whether the bets that survive can be run together.
Dark Matter in Drug Development: The Invisible Dependencies Driving Your Portfolio. On dependencies you cannot see. This narrows to the resource edge at the moment of decision.
Estimating Is Not Calculating: The Resource Precision Gap Between Planning and Execution. On why a parametric average is not a calculation, the same gap, here scaled to the whole portfolio.

Compliance
Unipr is built on trust, privacy, and enterprise-grade compliance. We never train our models on your data.






Start Building Today
Log in or create a free account to scope, build, map, compare, and enrich your projects with Planner.